用法
目录
用法¶
在这里,我们将介绍一个典型的用户工作流程。这假设您已经安装了 dask-gateway 客户端库(参见 安装),并且有一个正在运行的 dask-gateway-server。对于客户端和服务器的完全本地设置(用于演示、测试等),请参见 本地安装 (快速入门)。
连接到 dask-gateway 服务器¶
用户通过 dask-gateway 客户端库与 dask-gateway-server 交互。通常,一个会话以创建 Gateway 客户端开始。这需要几个参数:
address: dask-gateway 服务器的完整地址。proxy_address: dask-gateway 调度器代理的完整地址。如果未提供,则默认为address。auth: 使用的认证方法。
这些参数的值取决于您的部署 - 请咨询您的管理员以获取有关您特定部署的更多信息。
from dask_gateway import Gateway
# -- Here we provide a few examples of creating a `Gateway` object --
# Gateway server running at http://mygateway.com with kerberos authentication
gateway = Gateway(
address="http://mygateway.com",
auth="kerberos"
)
# Gateway server at http://146.148.58.187, proxy at
# tls://35.202.68.87:8786, with JupyterHub authentication
gateway = Gateway(
"http://146.148.58.187",
proxy_address="tls://35.202.68.87:8786",
auth="jupyterhub",
)
通常这些参数在 配置 中一次性设置好,之后就可以无需参数创建 Gateway 对象了。
from dask_gateway import Gateway
# Use values stored in your local configuration (recommended)
gateway = Gateway()
要检查一切是否设置正确,请查询 gateway 以查看任何现有集群。如果此调用完成,您应该拥有一个正确配置的 gateway 客户端。
>>> gateway.list_clusters()
[]
创建一个新集群¶
要创建一个新集群,可以使用 Gateway.new_cluster() 方法。这将创建一个没有 worker 的新集群。
>>> cluster = gateway.new_cluster()
>>> cluster
GatewayCluster<6c14f41343ea462599f126818a14ebd2>
或者,您可以跳过创建 Gateway 对象,直接使用 GatewayCluster 构造函数。
>>> from dask_gateway import GatewayCluster
# Create a new cluster using the GatewayCluster constructor directly
>>> cluster = GatewayCluster()
这两种方法的选择主要取决于个人偏好。如果您只需要与 gateway 服务器交互来创建一个新集群,那么使用 GatewayCluster 可能更简单。如果您需要执行其他操作(例如查询正在运行的集群),则可能希望使用 Gateway。
配置集群¶
一些 dask-gateway-server 部署允许用户在启动时配置集群。典型的选项可能包括指定 worker 的内存/核心数或使用哪个 Docker 镜像。要查看您的服务器支持哪些选项(如果有),可以使用 Gateway.cluster_options() 方法。
>>> options = gateway.cluster_options()
>>> options
Options<worker_cores=1, worker_memory=1.0, environment='basic'>
这将返回一个 Options 对象,它描述了可用的选项。Options 对象是一个 MutableMapping,也支持通过属性访问字段。
# Both attribute and key access works
>>> options.worker_cores
1
>>> options["worker_cores"]
1
# Can change values using attribute or key access
>>> options.worker_cores = 2
>>> options.worker_cores
2
请注意,字段的验证在客户端和服务器端都会进行。例如,如果在数字字段上设置了限制(例如最大 worker_cores),那么如果超出该限制,会抛出一个友好的错误。
>>> options.worker_cores = 10
Traceback (most recent call last):
...
ValueError: worker_cores must be <= 4, got 10
如果您在 Jupyter Notebook 或 JupyterLab 中进行交互式工作并且安装了 ipywidgets,您还可以使用提供的 widget 来配置您的集群。

一旦 Options 对象设置了所需的值,您可以将其传递给 Gateway.new_cluster() 或 GatewayCluster,以便在创建新集群时使用这些值。
# Using Gateway.new_cluster
>>> cluster = gateway.new_cluster(options)
# Or using the GatewayCluster constructor
>>> cluster = GatewayCluster(cluster_options=options)
或者,如果您知道 dask-gateway-server 部署中可配置的选项,您可以直接将值作为关键字参数传递给这两个方法。
# Using Gateway.new_cluster
>>> cluster = gateway.new_cluster(worker_cores=2, environment="tensorflow")
# Or using the GatewayCluster constructor
>>> cluster = GatewayCluster(worker_cores=2, environment="tensorflow")
扩展集群¶
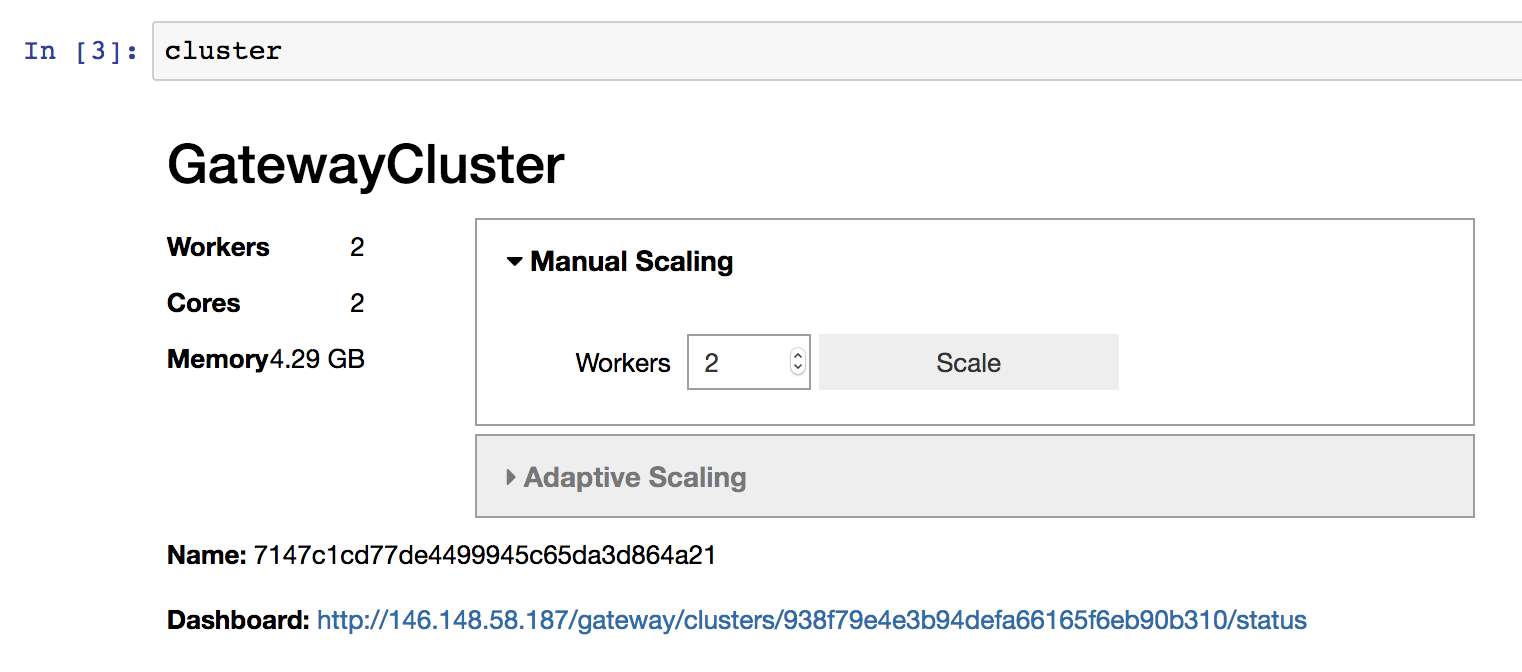
要将集群扩展到一个或多个 worker,您可以使用 GatewayCluster.scale() 方法。这里我们将集群扩展到两个 worker。
>>> cluster.scale(2)
如果您在 Jupyter Notebook 或 JupyterLab 中进行交互式工作并且安装了 ipywidgets,您还可以使用提供的 widget 来更改集群大小,而不是以编程方式调用 GatewayCluster.scale()。
启用自适应扩展¶
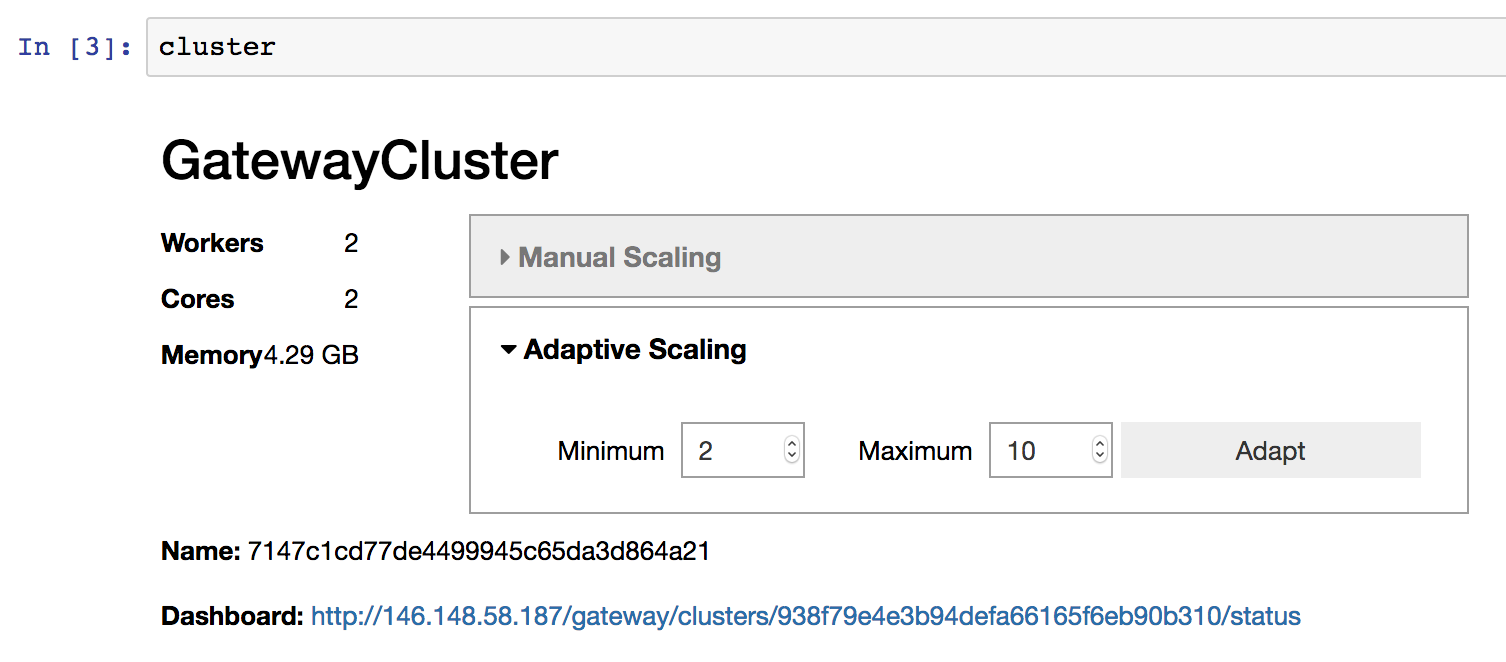
或者,您可以使用 自适应扩展,允许您的集群根据负载自动扩展/缩减。这有助于仅使用当前工作负载所需的资源,从而减少资源消耗。要启用自适应扩展,您可以使用 GatewayCluster.adapt() 方法。
# Adaptively scale between 2 and 10 workers
>>> cluster.adapt(minimum=2, maximum=10)
与上面的手动扩展一样,如果您在 notebook 环境中工作,您也可以使用提供的 widget 来启用自适应扩展,而不是以编程方式调用 GatewayCluster.adapt()。
如果您希望稍后禁用自适应扩展,可以传递 active=False。
# Disable adaptive scaling
>>> cluster.adapt(active=False)
连接到集群¶
要连接到集群以便开始工作,您可以使用 GatewayCluster.get_client() 方法。这将返回一个 dask.distributed.Client 对象。
>>> client = cluster.get_client()
>>> client
<Client: scheduler='tls://198.51.100.1:65252' processes=2 cores=2>
在集群上运行计算¶
此时,您应该能够使用正常的 dask 方法来完成工作。例如,这里我们计算一个随机数组的平均值。
>>> import dask.array as da
>>> a = da.random.normal(size=(1000, 1000), chunks=(500, 500))
>>> a.mean().compute()
0.0022336223893512945
关闭集群¶
当您使用完毕后,可以使用 Cluster.shutdown() 方法关闭集群。这将干净地关闭所有 dask worker 和调度器。
>>> cluster.shutdown()
请注意,当 GatewayCluster 对象用作上下文管理器时,在上下文退出时将自动调用 shutdown。
with gateway.new_cluster() as cluster:
client = cluster.get_client()
# ...
或者,当客户端进程关闭时,残留的集群对象将自动关闭。显式地清理是良好的实践,但并非严格必要。如果您希望集群的生命周期长于客户端进程的生命周期,请在调用 Gateway.new_cluster() 时设置 shutdown_on_close=False。
连接到现有集群¶
或者,您可以让一个集群继续运行,稍后再重新连接。为此,在调用 Gateway.new_cluster() 时设置 shutdown_on_close=False - 这允许 Dask 集群的生命周期长于客户端进程的生命周期。
# Create a new cluster which will persist longer than the lifetime of the
# client process
cluster = gateway.new_cluster(shutdown_on_close=False)
要连接到正在运行的集群,您需要集群的名称(一个唯一标识符)。如果您不知道,可以使用 Gateway.list_clusters() 方法查看所有正在运行的集群。
>>> clusters = gateway.list_clusters()
>>> clusters
[ClusterReport<name=ce498e95403741118a8f418ee242e646, status=RUNNING>]
然后,您可以使用 Gateway.connect() 方法连接到现有集群。
>>> cluster = gateway.connect(clusters[0].name)
>>> cluster
GatewayCluster<ce498e95403741118a8f418ee242e646>